Can a Machine Multiply Input Force? Input Distance? Input Energy?
How Transformers Work
The Neural Network used by Open AI and DeepMind
![]()
If you liked this post and want to acquire how machine learning algorithms work, how did they arise, and where are they going, I recommend the following:
Transformers are a type of neural network architecture that have been gaining popularity. Transformers were recently used by OpenAI in their language models, and also used recently by DeepMind for AlphaStar — their plan to defeat a elevation professional Starcraft player.
Transformers were developed to s o lve the trouble of sequence transduction , or neural car translation. That ways whatsoever chore that transforms an input sequence to an output sequence. This includes speech recognition, text-to-speech transformation, etc..

For models to perform sequence transduction, it is necessary to have some sort of memory. For example let's say that we are translating the following judgement to another linguistic communication (French):
"The Transformers" are a Japanese [[hardcore punk]] band. The band was formed in 1968, during the height of Japanese music history"
In this example, the word "the ring" in the second sentence refers to the band "The Transformers" introduced in the first sentence. When yous read about the band in the second sentence, y'all know that information technology is referencing to the "The Transformers" band. That may be important for translation. There are many examples, where words in some sentences refer to words in previous sentences.
For translating sentences like that, a model needs to figure out these sort of dependencies and connections. Recurrent Neural Networks (RNNs) and Convolutional Neural Networks (CNNs) have been used to deal with this problem because of their properties. Let's become over these two architectures and their drawbacks.
Recurrent Neural Networks
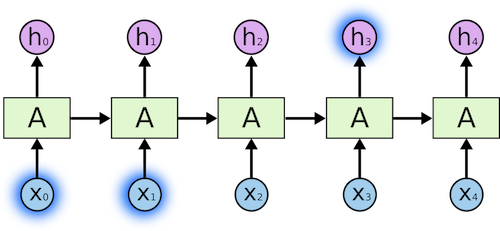
Recurrent Neural Networks have loops in them, allowing information to persist.
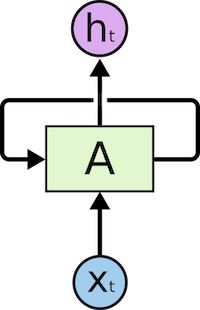
In the figure above, we meet part of the neural network, A, processing some input x_t and outputs h_t. A loop allows information to be passed from one step to the next.
The loops can be thought in a different way. A Recurrent Neural Network can be thought of as multiple copies of the same network, A, each network passing a message to a successor. Consider what happens if we unroll the loop:
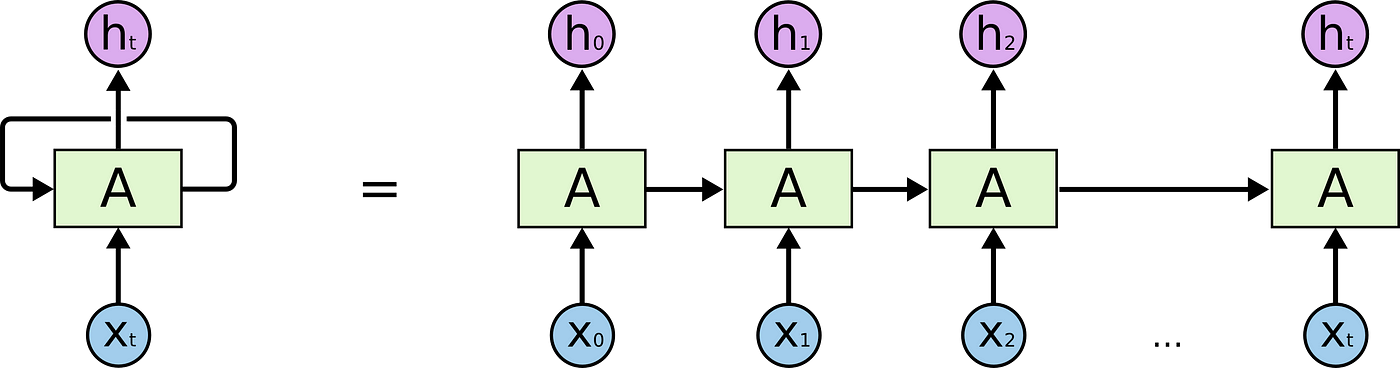
This concatenation-like nature shows that recurrent neural networks are conspicuously related to sequences and lists. In that way, if we want to translate some text, we can set up each input as the discussion in that text. The Recurrent Neural Network passes the information of the previous words to the side by side network that can use and process that data.
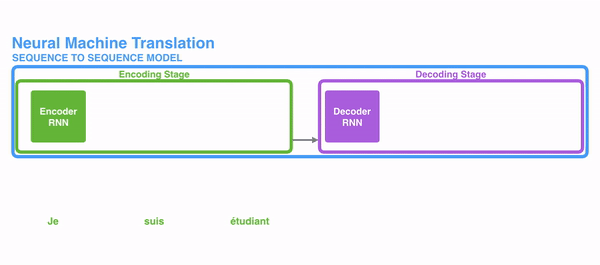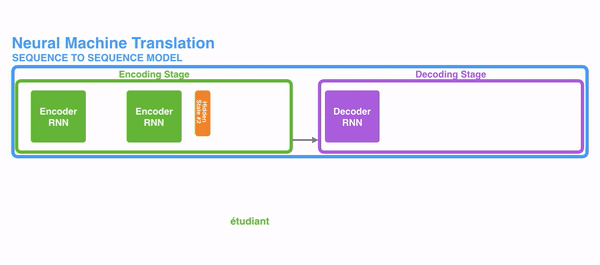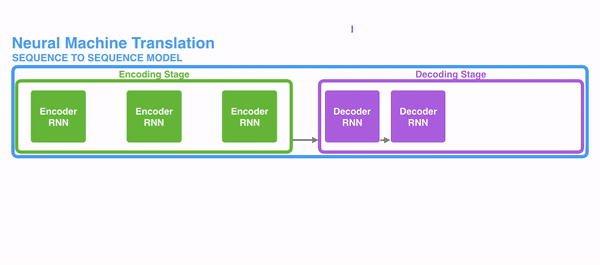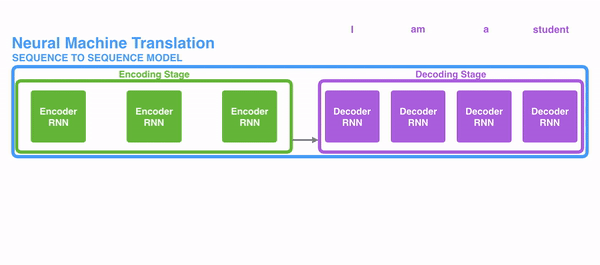
The following pic shows how ordinarily a sequence to sequence model works using Recurrent Neural Networks. Each discussion is processed separately, and the resulting sentence is generated by passing a subconscious state to the decoding stage that, then, generates the output.
The trouble of long-term dependencies
Consider a linguistic communication model that is trying to predict the next word based on the previous ones. If we are trying to predict the side by side word of the sentence "the clouds in the sky", we don't need further context. It's pretty obvious that the next give-and-take is going to be heaven.
In this case where the divergence between the relevant data and the identify that is needed is pocket-sized, RNNs can learn to employ by data and effigy out what is the side by side word for this sentence.
Just in that location are cases where we need more context. For case, let's say that you are trying to predict the terminal give-and-take of the text: "I grew up in France… I speak fluent …". Recent information suggests that the next word is probably a linguistic communication, but if nosotros want to narrow down which language, we demand context of France, that is further dorsum in the text.
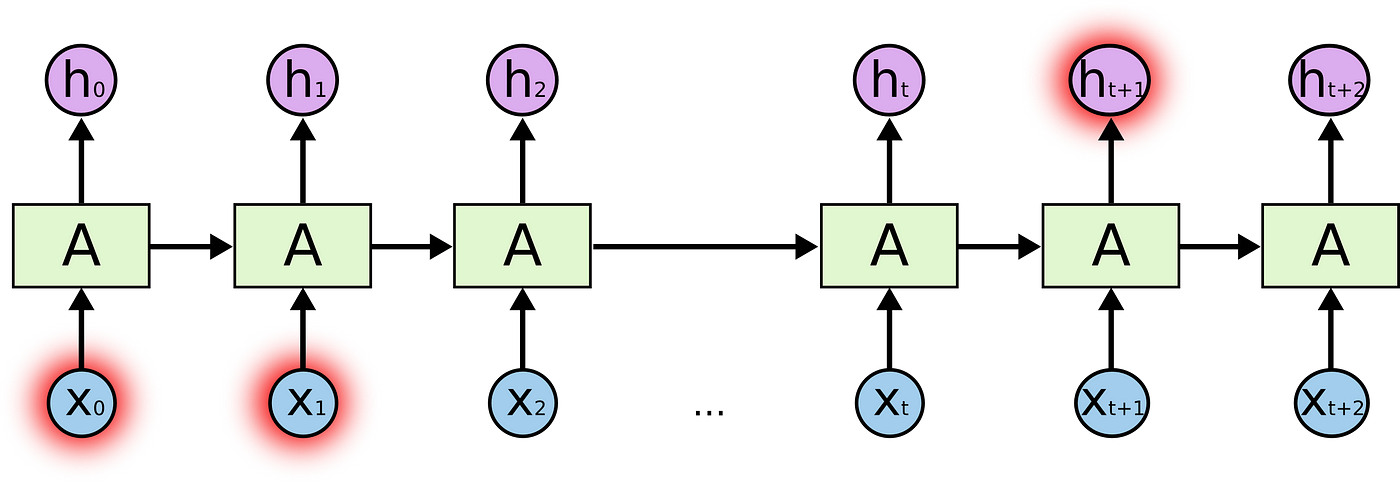
RNNs become very ineffective when the gap between the relevant information and the point where it is needed become very big. That is due to the fact that the data is passed at each step and the longer the chain is, the more likely the information is lost along the concatenation.
In theory, RNNs could learn this long-term dependencies. In practice, they don't seem to learn them. LSTM, a special type of RNN, tries to solve this kind of trouble.
Long-Short Term Memory (LSTM)
When arranging one's calendar for the day, we prioritize our appointments. If in that location is anything important, we can cancel some of the meetings and adapt what is important.
RNNs don't exercise that. Whenever it adds new information, information technology transforms existing information completely by applying a function. The unabridged information is modified, and there is no consideration of what is important and what is non.
LSTMs brand small modifications to the information by multiplications and additions. With LSTMs, the information flows through a machinery known as cell states. In this way, LSTMs can selectively call up or forget things that are important and non so important.
Internally, a LSTM looks similar the following:
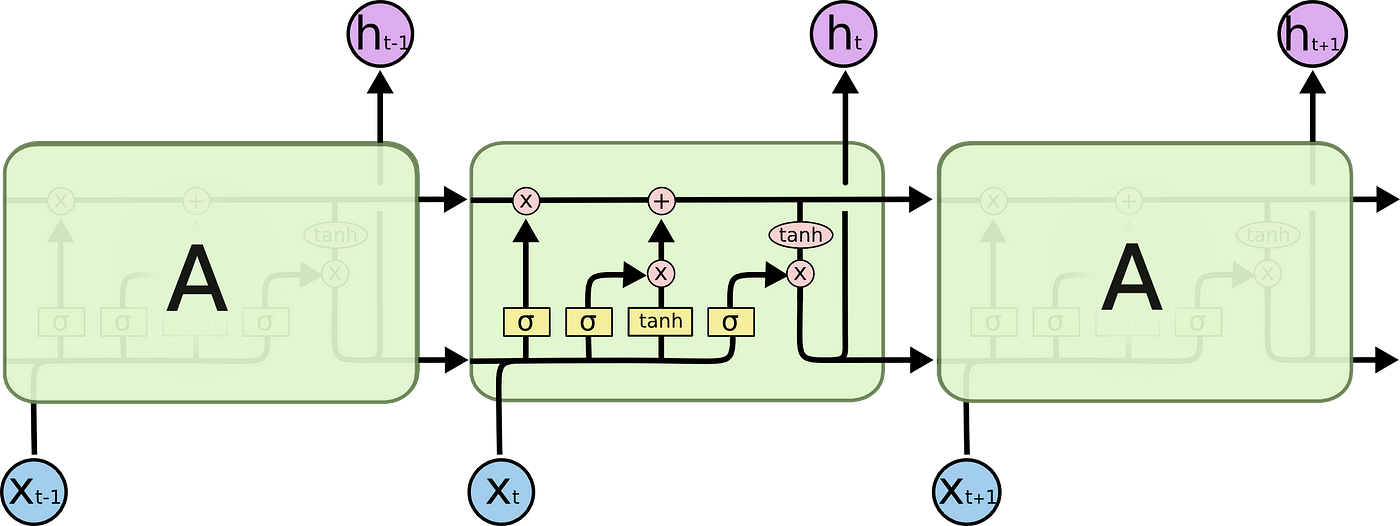
Each jail cell takes equally inputs x_t (a word in the case of a sentence to sentence translation), the previous cell country and the output of the previous jail cell. It manipulates these inputs and based on them, information technology generates a new jail cell state, and an output. I won't get into detail on the mechanics of each jail cell. If you want to understand how each jail cell works, I recommend Christopher'south web log post:
With a prison cell country, the information in a sentence that is important for translating a word may exist passed from one word to another, when translating.
The trouble with LSTMs
The same trouble that happens to RNNs generally, happen with LSTMs, i.eastward. when sentences are too long LSTMs still don't do besides well. The reason for that is that the probability of keeping the context from a give-and-take that is far abroad from the current word being candy decreases exponentially with the distance from it.
That means that when sentences are long, the model often forgets the content of distant positions in the sequence. Another trouble with RNNs, and LSTMs, is that it'south hard to parallelize the piece of work for processing sentences, since y'all are have to process word by word. Not merely that simply in that location is no model of long and brusque range dependencies. To summarize, LSTMs and RNNs present 3 issues:
- Sequential computation inhibits parallelization
- No explicit modeling of long and short range dependencies
- "Distance" betwixt positions is linear
Attention
To solve some of these issues, researchers created a technique for paying attending to specific words.
When translating a sentence, I pay special attending to the word I'g soon translating. When I'grand transcribing an audio recording, I listen carefully to the segment I'm actively writing down. And if y'all ask me to draw the room I'thousand sitting in, I'll glance around at the objects I'm describing every bit I do so.
Neural networks tin achieve this same beliefs using attention , focusing on role of a subset of the information they are given. For example, an RNN can attend over the output of another RNN. At every time step, it focuses on different positions in the other RNN.
To solve these bug, Attention is a technique that is used in a neural network. For RNNs, instead of merely encoding the whole sentence in a subconscious country, each give-and-take has a corresponding hidden state that is passed all the way to the decoding stage. Then, the hidden states are used at each step of the RNN to decode. The following gif shows how that happens.
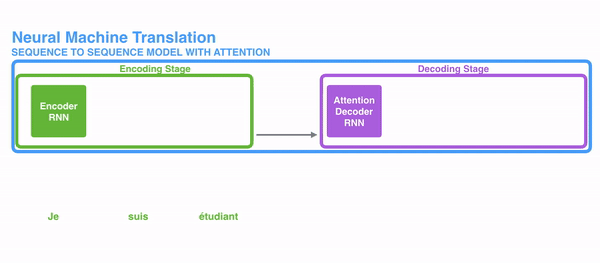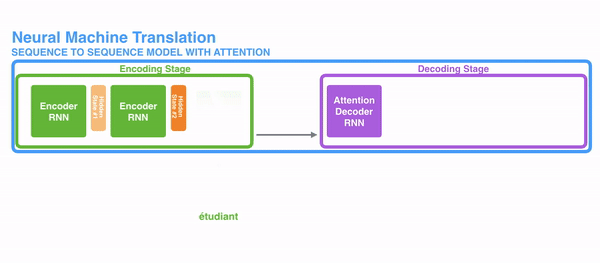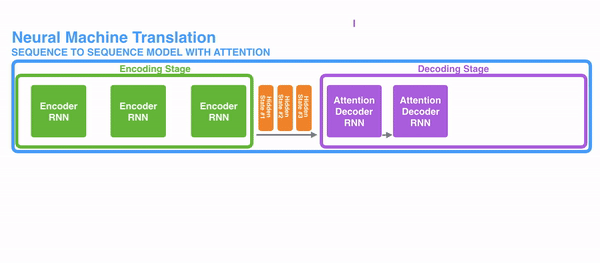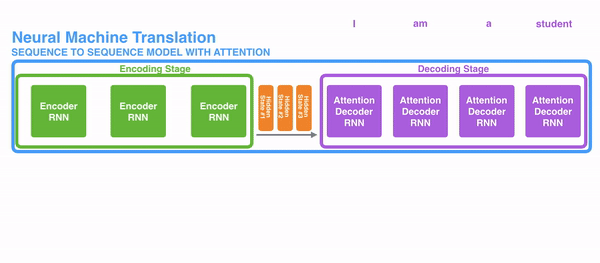
The thought behind it is that there might be relevant information in every give-and-take in a judgement. And then in order for the decoding to be precise, it needs to take into account every word of the input, using attention.
For attending to be brought to RNNs in sequence transduction, we divide the encoding and decoding into 2 main steps. One step is represented in dark-green and the other in majestic. The green step is called the encoding stage and the majestic pace is the decoding stage.

The step in green in accuse of creating the hidden states from the input. Instead of passing only one subconscious state to the decoders as we did before using attending, we laissez passer all the hidden states generated past every "word" of the judgement to the decoding stage. Each hidden state is used in the decoding stage, to figure out where the network should pay attending to.
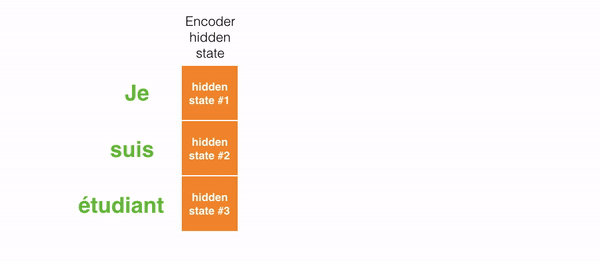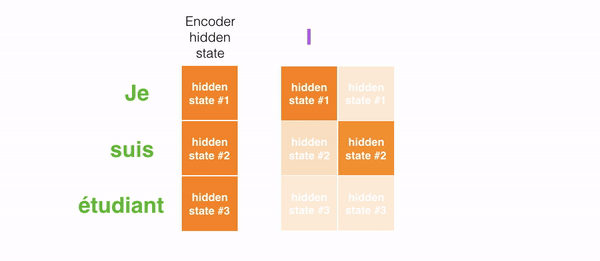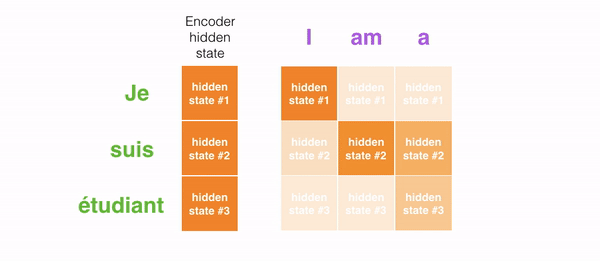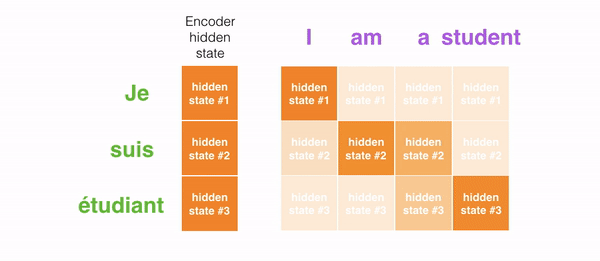
For instance, when translating the sentence "Je suis étudiant" to English, requires that the decoding step looks at unlike words when translating information technology.
Or for example, when you lot translate the sentence "L'accord sur la zone économique européenne a été signé en août 1992." from French to English, and how much attending it is paid to each input.

But some of the problems that we discussed, yet are non solved with RNNs using attention. For example, processing inputs (words) in parallel is not possible. For a large corpus of text, this increases the time spent translating the text.
Convolutional Neural Networks
Convolutional Neural Networks help solve these problems. With them we can
- Trivial to parallelize (per layer)
- Exploits local dependencies
- Altitude between positions is logarithmic
Some of the most popular neural networks for sequence transduction, Wavenet and Bytenet, are Convolutional Neural Networks.

The reason why Convolutional Neural Networks can work in parallel, is that each word on the input tin be processed at the same time and does not necessarily depend on the previous words to be translated. Non only that, but the "distance" between the output word and any input for a CNN is in the guild of log(N) — that is the size of the top of the tree generated from the output to the input (you can see it on the GIF to a higher place. That is much ameliorate than the distance of the output of a RNN and an input, which is on the social club of N .
The problem is that Convolutional Neural Networks do not necessarily help with the trouble of figuring out the problem of dependencies when translating sentences. That's why Transformers were created, they are a combination of both CNNs with attention.
Transformers
To solve the problem of parallelization, Transformers effort to solve the problem by using Convolutional Neural Networks together with attention models. Attention boosts the speed of how fast the model can interpret from ane sequence to another.
Allow's have a look at how Transformer works. Transformer is a model that uses attention to heave the speed. More than specifically, it uses cocky-attention.

Internally, the Transformer has a similar kind of architecture as the previous models above. But the Transformer consists of vi encoders and six decoders.
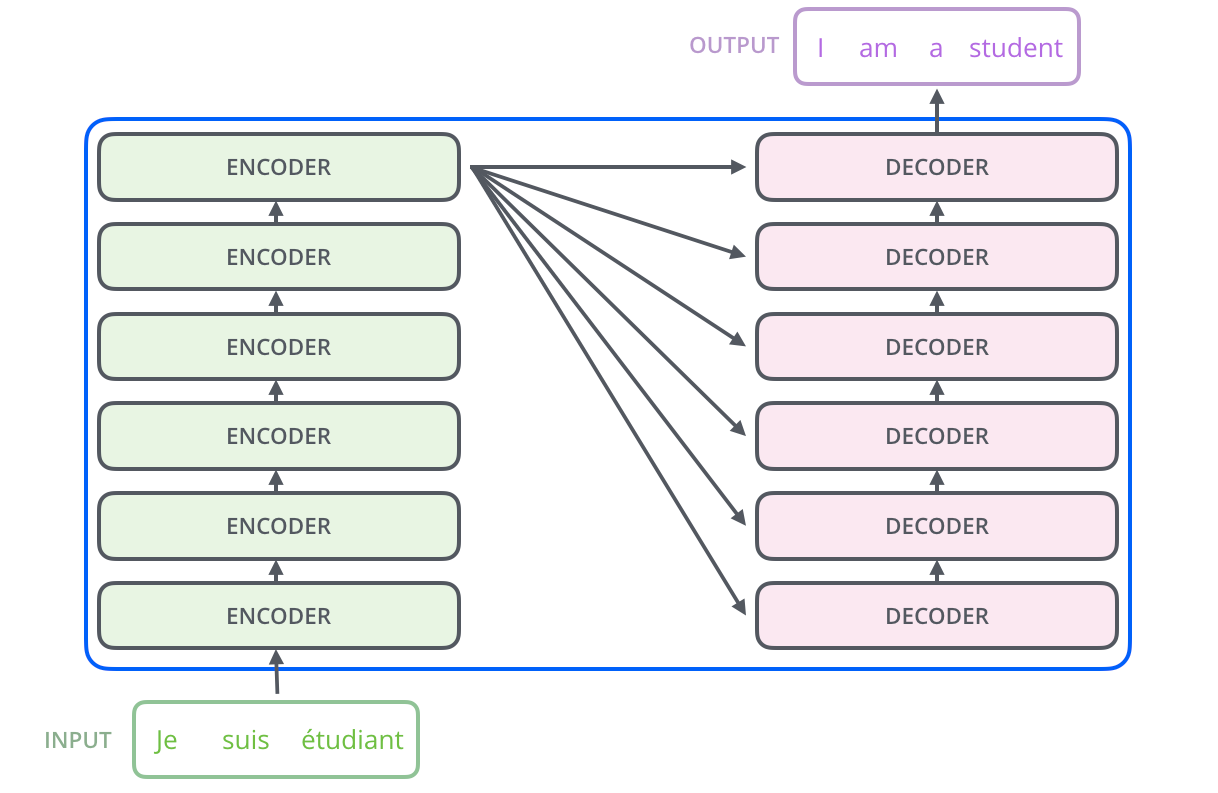
Each encoder is very like to each other. All encoders have the same architecture. Decoders share the same property, i.e. they are also very similar to each other. Each encoder consists of two layers: Cocky-attention and a feed Frontwards Neural Network.
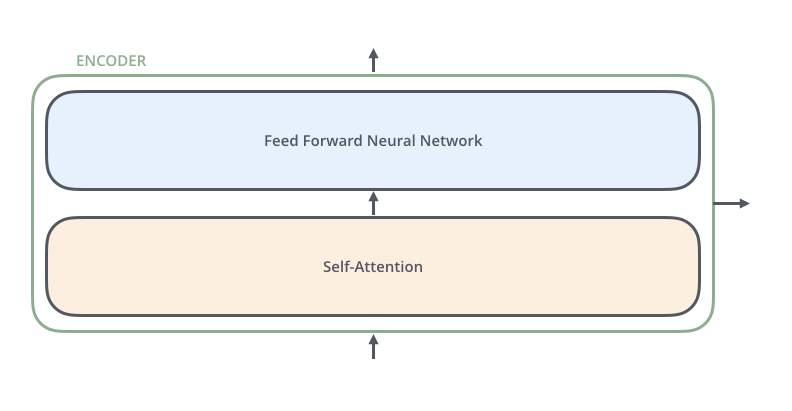
The encoder'due south inputs first menses through a cocky-attending layer. Information technology helps the encoder wait at other words in the input sentence as it encodes a specific give-and-take. The decoder has both those layers, just between them is an attending layer that helps the decoder focus on relevant parts of the input sentence.
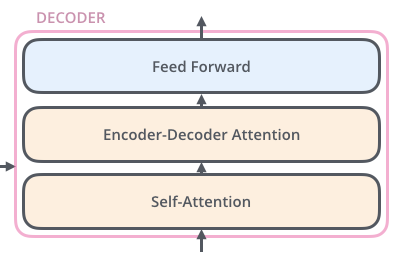
Self-Attention
Notation: This department comes from Jay Allamar blog postal service
Permit's beginning to look at the various vectors/tensors and how they flow between these components to plow the input of a trained model into an output. Equally is the instance in NLP applications in full general, we begin by turning each input discussion into a vector using an embedding algorithm.

Each word is embedded into a vector of size 512. We'll correspond those vectors with these simple boxes.
The embedding just happens in the lesser-most encoder. The abstraction that is common to all the encoders is that they receive a listing of vectors each of the size 512.
In the bottom encoder that would be the word embeddings, but in other encoders, it would be the output of the encoder that's directly beneath. After embedding the words in our input sequence, each of them flows through each of the two layers of the encoder.

Here we brainstorm to see 1 key belongings of the Transformer, which is that the discussion in each position flows through its own path in the encoder. In that location are dependencies between these paths in the self-attention layer. The feed-forwards layer does not have those dependencies, yet, and thus the various paths can be executed in parallel while flowing through the feed-forwards layer.
Next, we'll switch upwards the example to a shorter sentence and we'll expect at what happens in each sub-layer of the encoder.
Self-Attention
Allow's beginning look at how to calculate cocky-attention using vectors, then proceed to look at how it's actually implemented — using matrices.
The first pace in computing self-attending is to create three vectors from each of the encoder'southward input vectors (in this case, the embedding of each word). So for each word, nosotros create a Query vector, a Primal vector, and a Value vector. These vectors are created by multiplying the embedding by 3 matrices that nosotros trained during the grooming process.
Notice that these new vectors are smaller in dimension than the embedding vector. Their dimensionality is 64, while the embedding and encoder input/output vectors take dimensionality of 512. They don't HAVE to be smaller, this is an compages choice to make the computation of multiheaded attending (mostly) constant.
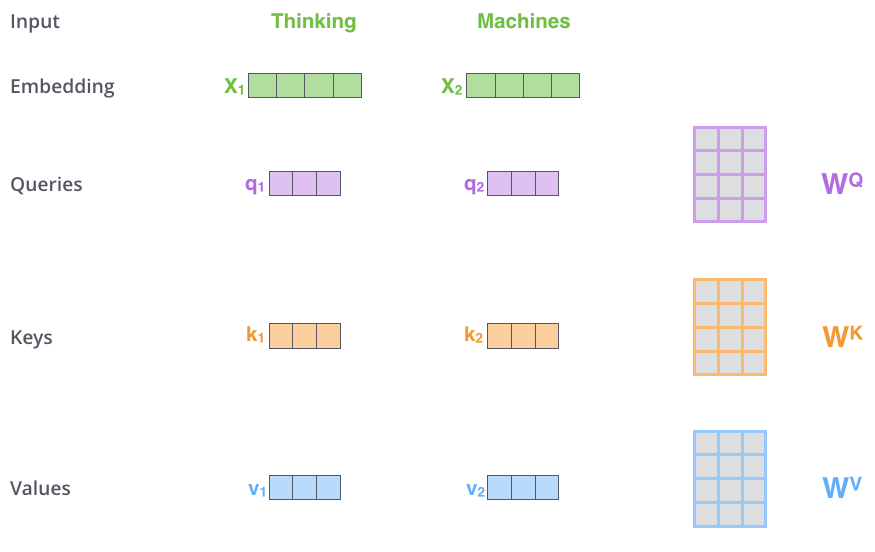
Multiplying x1 by the WQ weight matrix produces q1, the "query" vector associated with that word. We end up creating a "query", a "cardinal", and a "value" project of each give-and-take in the input sentence.
What are the "query", "cardinal", and "value" vectors?
They're abstractions that are useful for calculating and thinking about attention. Once yous proceed with reading how attention is calculated beneath, y'all'll know pretty much all you need to know about the office each of these vectors plays.
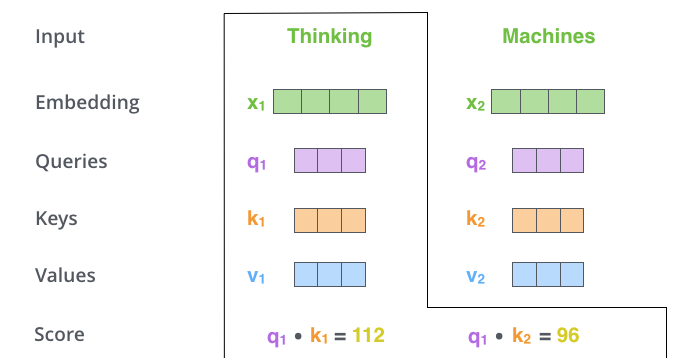
The second footstep in calculating cocky-attention is to calculate a score. Say nosotros're computing the self-attention for the offset word in this example, "Thinking". We need to score each word of the input judgement confronting this word. The score determines how much focus to place on other parts of the input sentence as we encode a word at a certain position.
The score is calculated by taking the dot product of the query vector with the key vector of the respective discussion we're scoring. So if we're processing the self-attention for the give-and-take in position #i, the first score would be the dot production of q1 and k1. The second score would be the dot product of q1 and k2.
The third and forth steps are to divide the scores by viii (the square root of the dimension of the central vectors used in the paper — 64. This leads to having more stable gradients. There could be other possible values here, just this is the default), then laissez passer the issue through a softmax operation. Softmax normalizes the scores so they're all positive and add up to i.
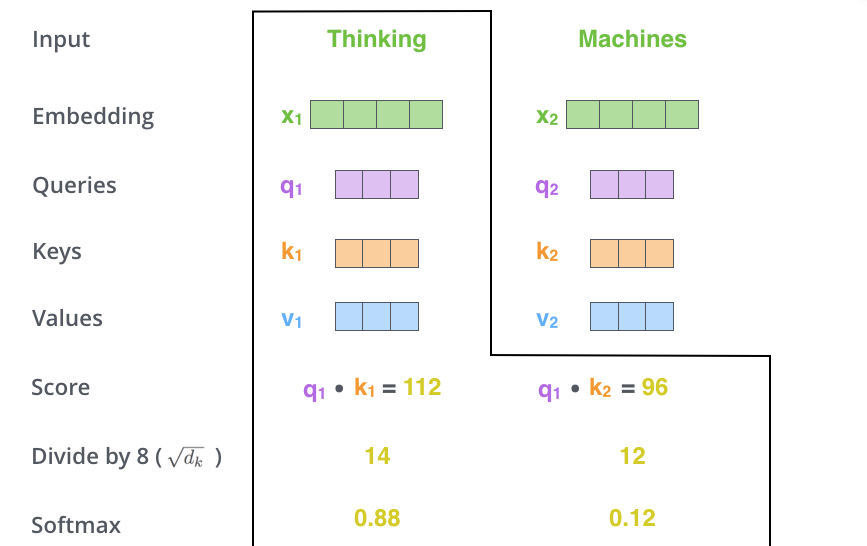
This softmax score determines how much how much each word will exist expressed at this position. Clearly the word at this position will have the highest softmax score, but sometimes information technology's useful to nourish to another give-and-take that is relevant to the electric current word.
The fifth step is to multiply each value vector by the softmax score (in training to sum them up). The intuition hither is to keep intact the values of the give-and-take(s) we desire to focus on, and drown-out irrelevant words (by multiplying them past tiny numbers like 0.001, for example).
The sixth stride is to sum up the weighted value vectors. This produces the output of the self-attention layer at this position (for the starting time discussion).
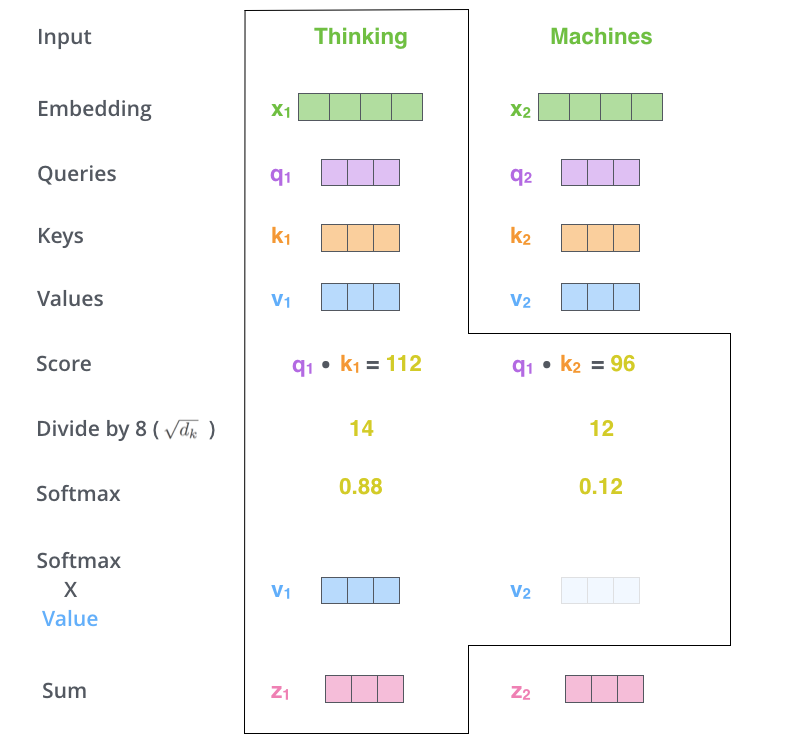
That concludes the cocky-attention calculation. The resulting vector is ane we tin can send along to the feed-frontward neural network. In the actual implementation, yet, this calculation is done in matrix form for faster processing. So let's wait at that now that we've seen the intuition of the calculation on the discussion level.
Multihead attending
Transformers basically piece of work like that. In that location are a few other details that make them work improve. For example, instead of but paying attention to each other in ane dimension, Transformers use the concept of Multihead attention.
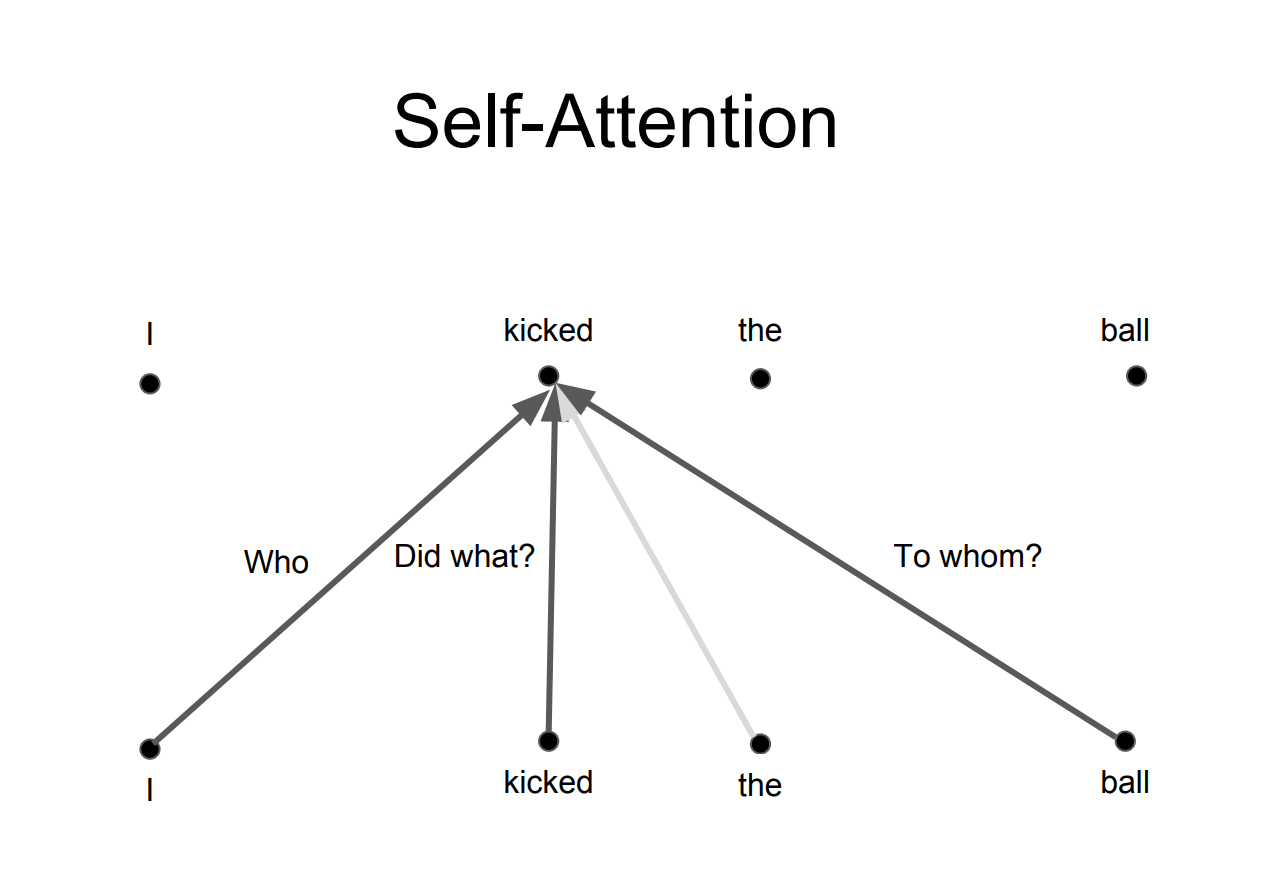
The idea behind it is that whenever you are translating a word, yous may pay different attention to each word based on the blazon of question that you are asking. The images below show what that means. For example, whenever y'all are translating "kicked" in the judgement "I kicked the ball", y'all may ask "Who kicked". Depending on the answer, the translation of the give-and-take to some other linguistic communication tin can change. Or enquire other questions, similar "Did what?", etc…

Source: https://towardsdatascience.com/transformers-141e32e69591
0 Response to "Can a Machine Multiply Input Force? Input Distance? Input Energy?"
Post a Comment