C++ Easiest Way to Read Tab Separated Tables
Importing data
Although creating data frames from existing information structures is extremely useful, by far the most common approach is to create a information frame by importing data from an external file. To do this, yous'll need to take your data correctly formatted and saved in a file format that R is able to recognise. Fortunately for us, R is able to recognise a wide variety of file formats, although in reality you'll probably end upwards merely using 2 or 3 regularly.
Accept a wait at this video for a quick introduction to importing data in R
Saving files to import
The easiest method of creating a data file to import into R is to enter your data into a spreadsheet using either Microsoft Excel or LibreOffice Calc and save the spreadsheet as a tab delimited file. We prefer LibreOffice Calc every bit it's open up source, platform contained and gratis but MS Excel is OK too (but see here for some gotchas). Here's the data from the petunia experiment we dicussed previously displayed in LibreOffice. If you want to follow along yous can download the data file ('bloom.xls') from the companion website here.
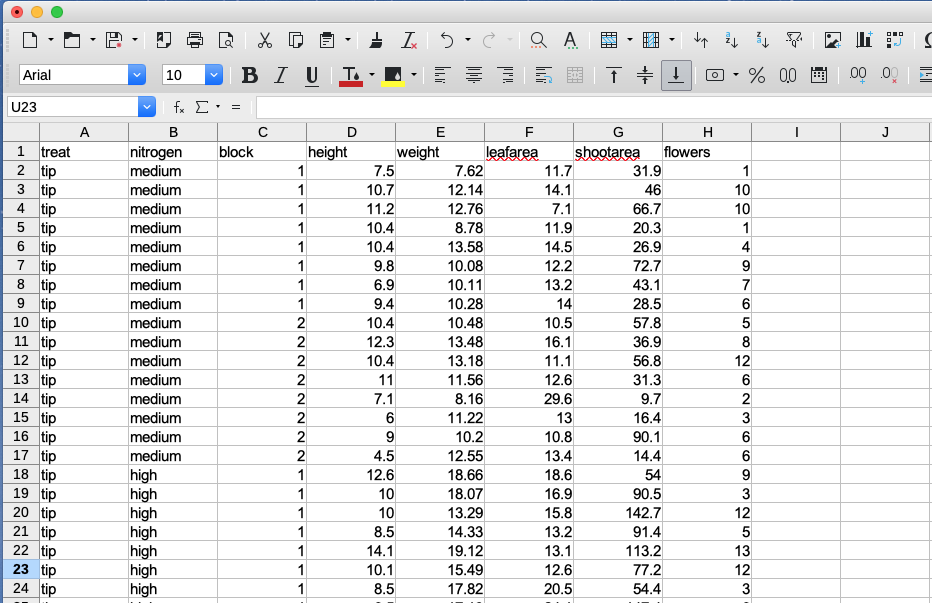
For those of you unfamiliar with the tab delimited file format it only means that information in different columns are separated with a 'tab' character (yep, the aforementioned ane as on your keyboard) and is usually saved as a file with a '.txt' extension (y'all might likewise see .tsv which is short for tab separated values).
To salvage a spreadsheet every bit a tab delimited file in LibreOffice Calc select File -> Save as ... from the main menu. You will need to specify the location you want to save your file in the 'Relieve in folder' pick and the proper noun of the file in the 'Name' option. In the drop down carte located to a higher place the 'Save' push alter the default 'All formats' to 'Text CSV (.csv)'.
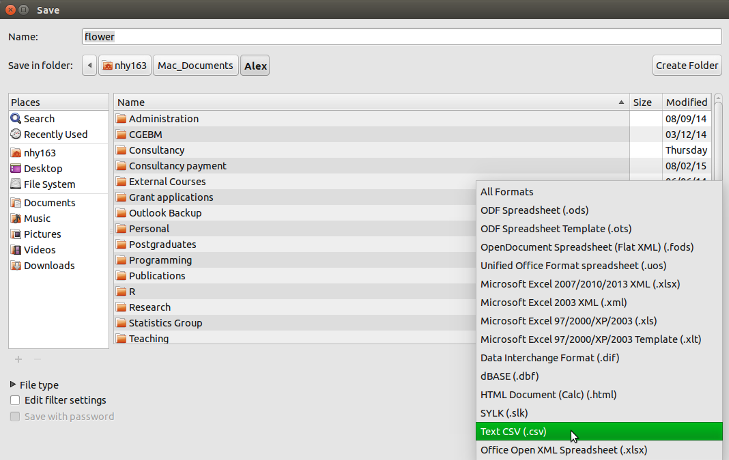
Click the Salvage push button and then select the 'Utilize Text CSV Format' option. In the next pop-up window select {Tab} from the drop down card in the 'Field delimiter' option. Click on OK to save the file.
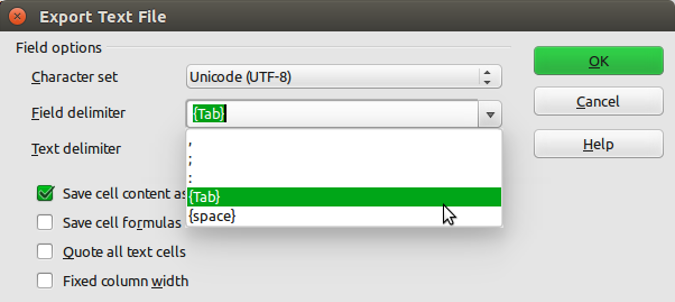
The resulting file will annoyingly have a '.csv' extension even though we've saved it as a tab delimited file. Either alive with it or rename the file with a '.txt' extension instead.
In MS Excel, select File -> Save as ... from the main menu and navigate to the folder where you want to save the file. Enter the file name (keep it fairly short, no spaces!) in the 'Save equally:' dialogue box. In the 'File format:' dialogue box click on the down pointer to open up the drop down menu and select 'Text (Tab delimited)' equally your file type. Select OK to salvage the file.
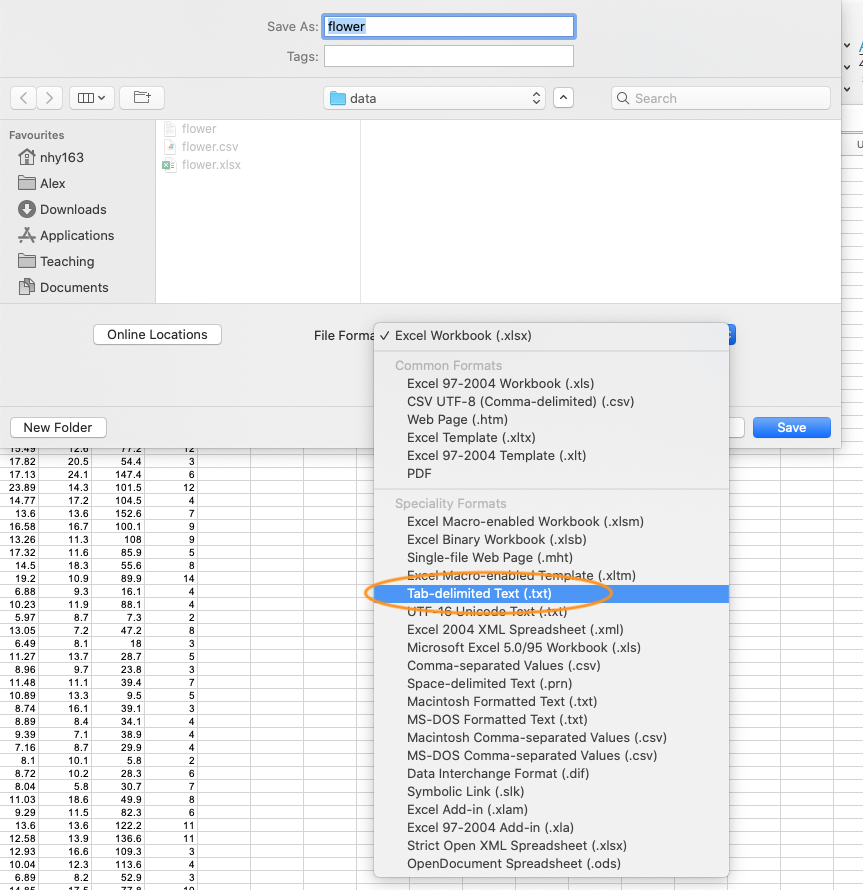
There are a couple of things to conduct in mind when saving files to import into R which volition make your life easier in the long run. Proceed your cavalcade headings (if you accept them) curt and informative. Also avoid spaces in your column headings by replacing them with an underscore or a dot (i.due east. supersede shoot height with shoot_height or shoot.height) and avoid using special characters (i.due east.leaf surface area (mm^2)). Retrieve, if you lot have missing information in your data frame (empty cells) yous should use an NA to represent these missing values. This volition go along the information frame tidy.
Import functions
One time yous've saved your data file in a suitable format we can now read this file into R. The workhorse office for importing data into R is the read.tabular array() function (we discuss some alternatives later on in the chapter). The read.tabular array() function is a very flexible role with a shed load of arguments (come across ?read.table) but it'southward quite simple to use. Let's import a tab delimited file called flower.txt which contains the information we saw previously in this Affiliate and assign it to an object called flowers. The file is located in a data directory which itself is located in our root directory. The get-go row of the data contains the variable (column) names. To use the read.table() function to import this file
flowers <- read.table(file = 'data/blossom.txt', header = True, sep = " \t ", stringsAsFactors = TRUE) There are a few things to annotation about the above command. First, the file path and the filename (including the file extension) needs to exist enclosed in either single or double quotes (i.due east. the information/flower.txt flake) as the read.table() function expects this to be a character cord. If your working directory is already set to the directory which contains the file, y'all don't need to include the entire file path just the filename. In the example higher up, the file path is separated with a single forrad slash /. This volition work regardless of the operating system yous are using and we recommend yous stick with this. However, Windows users may be more familiar with the single backslash note and if you want to keep using this you will need to include them as double backslashes. Note though that the double backslash notation will non piece of work on computers using Mac OSX or Linux operating systems.
flowers <- read.table(file = 'C: \\ Documents \\ Prog1 \\ information \\ bloom.txt', header = True, sep = " \t ", stringsAsFactors = Truthful) The header = Truthful argument specifies that the first row of your data contains the variable names (i.e.nitrogen, block etc). If this is not the case you can specify header = FALSE (actually, this is the default value so y'all tin can omit this argument entirely). The sep = "\t" argument tells R that the file delimiter is a tab (\t).
Later importing our data into R it doesn't announced that R has washed much, at least zero appears in the R Console! To see the contents of the data frame we could but type the name of the object as we accept done previously. BUT before you do that, call up about why yous're doing this. If your data frame is anything other than tiny, all yous're going to do is fill up up your Console with data. It's not like you can easily check whether in that location are any errors or that your data has been imported correctly. A much better solution is to use our old friend the str() role to return a meaty and informative summary of your data frame.
str(flowers) ## 'data.frame': 96 obs. of 8 variables: ## $ treat : Factor w/ 2 levels "notip","tip": ii two two ii 2 ii 2 2 ii 2 ... ## $ nitrogen : Factor west/ iii levels "high","low","medium": 3 3 3 3 3 three 3 3 3 3 ... ## $ block : int ane one 1 1 1 one 1 one 2 2 ... ## $ summit : num 7.five x.7 eleven.2 10.iv 10.4 nine.8 6.nine 9.iv ten.4 12.3 ... ## $ weight : num 7.62 12.14 12.76 8.78 thirteen.58 ... ## $ leafarea : num 11.7 14.one 7.one eleven.9 14.5 12.ii 13.2 14 10.v 16.ane ... ## $ shootarea: num 31.9 46 66.7 20.3 26.9 72.7 43.1 28.five 57.8 36.9 ... ## $ flowers : int ane 10 x 1 4 nine 7 6 5 eight ... Here nosotros see that flowers is a 'information.frame' object which contains 96 rows and 8 variables (columns). Each of the variables are listed along with their data class and the first 10 values. As nosotros mentioned previously in this Affiliate, information technology tin can be quite user-friendly to copy and paste this into your R script as a comment block for after reference.
Find also that your character cord variables (treat and nitrogen) take been imported every bit factors considering we used the argument stringsAsFactors = TRUE. If this is not what you want you can prevent this by using the stringsAsFactors = FALSE or from R version four.0.0 you can just leave out this argument as stringsAsFactors = Imitation is the default.
flowers <- read.table(file = 'data/flower.txt', header = TRUE, sep = " \t ", stringsAsFactors = FALSE) str(flowers) ## 'data.frame': 96 obs. of 8 variables: ## $ treat : chr "tip" "tip" "tip" "tip" ... ## $ nitrogen : chr "medium" "medium" "medium" "medium" ... ## $ block : int 1 1 1 one 1 i ane 1 2 2 ... ## $ height : num seven.5 x.7 xi.2 x.4 ten.four 9.eight 6.nine 9.iv 10.4 12.3 ... ## $ weight : num seven.62 12.fourteen 12.76 8.78 13.58 ... ## $ leafarea : num 11.vii 14.1 7.one 11.nine 14.5 12.2 xiii.2 xiv 10.5 16.1 ... ## $ shootarea: num 31.ix 46 66.7 xx.3 26.9 72.7 43.1 28.5 57.viii 36.9 ... ## $ flowers : int one 10 x 1 iv 9 seven 6 five 8 ... Other useful arguments include dec = and na.strings =. The dec = statement allows you to change the default grapheme (.) used for a decimal bespeak. This is useful if y'all're in a country where decimal places are usually represented by a comma (i.e.dec = ","). The na.strings = argument allows you to import data where missing values are represented with a symbol other than NA. This tin can be quite common if you are importing data from other statistical software such as Minitab which represents missing values every bit a * (na.strings = "*").
If we merely wanted to see the names of our variables (columns) in the data frame we can utilise the names() function which will return a character vector of the variable names.
names(flowers) ## [1] "treat" "nitrogen" "block" "height" "weight" "leafarea" ## [7] "shootarea" "flowers" R has a number of variants of the read.table() role that you can use to import a variety of file formats. Actually, these variants merely employ the read.table() function but include different combinations of arguments past default to aid import unlike file types. The about useful of these are the read.csv(), read.csv2() and read.delim() functions. The read.csv() function is used to import comma separated value (.csv) files and assumes that the information in columns are separated by a comma (it sets sep = "," by default). It also assumes that the first row of the data contains the variable names past default (it sets header = Truthful past default). The read.csv2() function assumes data are separated by semicolons and that a comma is used instead of a decimal point (every bit in many European countries). The read.delim() role is used to import tab delimited data and also assumes that the first row of the information contains the variable names by default.
# import .csv file flowers <- read.csv(file = 'information/bloom.csv') # import .csv file with dec = "," and sep = ";" flowers <- read.csv2(file = 'data/flower.csv') # import tab delim file with sep = "\t" flowers <- read.delim(file = 'data/blossom.txt') Y'all can even import spreadsheet files from MS Excel or other statistics software directly into R but our advice is that this should by and large be avoided if possible equally it simply adds a layer of dubiety betwixt you and your data. In our stance it's almost ever better to export your spreadsheets as tab or comma delimited files and then import them into R using the read.table() function. If you're hell bent on directly importing data from other software you volition need to install the strange package which has functions for importing Minitab, SPSS, Stata and SAS files or the xlsx package to import Excel spreadsheets.
Common import frustrations
It'southward quite mutual to get a bunch of really frustrating error messages when you lot first kickoff importing information into R. Peradventure the most common is
Error in file(file, "rt") : cannot open the connection In addition: Warning message: In file(file, "rt") : cannot open file 'blossom.txt' : No such file or directory This error message is telling you that R cannot find the file you are trying to import. It normally rears its head for one of a couple of reasons (or all of them!). The starting time is that you've made a error in the spelling of either the filename or file path. Another common mistake is that you have forgotten to include the file extension in the filename (i.e..txt). Lastly, the file is not where you say it is or you've used an incorrect file path. Using RStudio Projects and having a logical directory construction goes forth way to avoiding these types of errors.
Another actually common mistake is to forget to include the header = True argument when the first row of the information contains variable names. For example, if nosotros omit this statement when we import our flowers.txt file everything looks OK at offset (no mistake message at to the lowest degree)
flowers_bad <- read.table(file = 'data/flower.txt', sep = " \t ") but when we have a look at our data frame using str()
str(flowers_bad) ## 'data.frame': 97 obs. of eight variables: ## $ V1: chr "treat" "tip" "tip" "tip" ... ## $ V2: chr "nitrogen" "medium" "medium" "medium" ... ## $ V3: chr "block" "one" "1" "1" ... ## $ V4: chr "height" "vii.five" "10.7" "11.2" ... ## $ V5: chr "weight" "7.62" "12.14" "12.76" ... ## $ V6: chr "leafarea" "11.7" "14.1" "7.ane" ... ## $ V7: chr "shootarea" "31.9" "46" "66.7" ... ## $ V8: chr "flowers" "1" "x" "x" ... We tin run across an obvious trouble, all of our variables have been imported as factors and are variables are named V1, V2, V3 … V8. The problem happens because we haven't told the read.table() role that the first row contains the variable names and then it treats them as information. Equally presently as nosotros have a single character string in any of our information vectors, R treats the vectors equally character blazon information (remember all elements in a vector must contain the same type of data).
Other import options
There are numerous other functions to import information from a variety of sources and formats. Most of these functions are contained in packages that you volition need to install before using them. Nosotros list a couple of the more useful packages and functions below.
The fread() function from the read.table package is great for importing big data files quickly and efficiently (much faster than the read.table() function). Ane of the great things about the fread() role is that information technology will automatically detect many of the arguments you would normally need to specify (like sep = etc). Ane of the things yous will need to consider though is that the fread() role volition return a data.table object not a information.frame equally would exist the case with the read.table() part. This is usually not a problem every bit you tin can pass a data.tabular array object to any function that only accepts data.frame objects. To acquire more about the differences between data.tabular array and data.frame objects meet here.
library(read.table) all_data <- fread(file = 'data/blossom.txt') Various functions from the readr package are also very efficient at reading in big data files. The readr package is part of the 'tidyverse' drove of packages and provides many equivalent functions to base R for importing information. The readr functions are used in a like way to the read.table() or read.csv() functions and many of the arguments are the aforementioned (see ?readr::read_table for more details). There are however some differences. For case, when using the read_table() function the header = TRUE argument is replaced by col_names = Truthful and the office returns a tibble class object which is the tidyverse equivalent of a data.frame object (see here for differences).
library(readr) # import white space delimited files all_data <- read_table(file = 'data/flower.txt', col_names = Truthful) # import comma delimited files all_data <- read_csv(file = 'information/flower.txt') # import tab delimited files all_data <- read_delim(file = 'information/flower.txt', delim = " \t ") # or use all_data <- read_tsv(file = 'information/flower.txt') If your data file is ginormous, then the ff and bigmemory packages may be useful as they both contain import functions that are able to store big data in a memory efficient mode. You tin discover out more nearly these functions here and here.
Source: https://intro2r.com/importing-data.html
0 Response to "C++ Easiest Way to Read Tab Separated Tables"
Post a Comment